Change VCSA FQDN and IP in a Nutanix Environment:
First, check everything is up an running and there are no problems at all.
Be sure, you have all needed credentials (SSO-Admin, Domain Admin. etc...)
Be sure you have the new fqdn and the new IP as well as the corresponding DNS-Entry. An eventually new VLAN should be available on your vSphere Environment.
First, take a backup (snapshot) of your VCSA.
Then uninstall vCenter Plugins an unregister your vCenter from your Nutanix PRISM:
Then leave the AD-Domain via the vSphere Webclient (logged in with SSO-Admin):
A reboot of the VCSA is required, you ca do this via VAMI (IP:5480) and the root user of the VCSA.
After the VCSA has rebooted and all services are started (Check via VAMI), we can continue to change the FQDN andf IP of the VCSA, we will perform this in VAMI -> Networking:
Be sure, your new IP and FQDN are resolvable via DNS!
Check, everything is correct before you press finish.
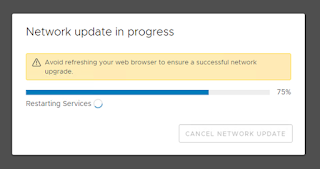
Then a progess window appears:
You should ping the old vCenter IP, if there is no more answer, you can login to the ESX-hostclient of the ESX-Server, where the VCSA is running and change the VLAN of the VCSA-VM.
Now ping the new IP-adress and you should reach it. You should be redirected after some time to the new IP/FQDN of the VCSA. If not, wait about 10 minutes and connect to the new fqdn-VAMI and logon, then you should see again the progress bar:
After finishing all tasks and restarting all services, you will be redirected to the login page and have to reauthenticate:
Now, you can check within VAMI, that the VCSA has a new fqdn and ip and all services are up and running:
The you can switch to webclient and check, everything is fine, too.
Then you have to join the AD-domain from webclient:
You have to perform a reboot of the VCSA after joining the domain, you perform this from VAMI.
After restarting, check, everything is running, then you eventually have to register your plugins and register the new VCSA in Nutanix PRISM:
Now you should be done, just check, your backup and monitoring is aware of the "new" vCenter.
If you are using custom certificates, you have to recertificate your vSphere-environment.
If some services didn't come up after changing FQDN and IP, you can try recertificate the VCSA also with selfsigned certificates, if you still have problems, you can go back to your snapshot and try again!
If all is working as desired, delete your snapshot!